


6月23日,在德国汉堡举行的ISC 2026会议上公布的2026年6月期TOP500超级计算机榜单中,中国超算“灵晟”(LineShine)以2.198 ExaFLOPS的高性能 Linpack (HPL) 基准测试成绩成功登顶,力压美国劳伦斯·利弗莫尔国家实验室的El Capitan系统。这也是中国超算时隔8年来真正意义上的再次重回全球超算TOP500榜单第一的位置。

需要指出的是,此后多年中国超算排名持续下滑,并不是完全是因为高性能芯片对华禁运导致超算实力下滑,而是在中美贸易战爆发后,中国自2021年开始就不再将新一代的、性能更强的超算(如“神威”新型号、“天河”新型号)提交给TOP500进行测试。虽然之后的TOP500榜单中,我们还能看到“神威·太湖之光,但那一直都是之前的未更新的数据。
此次,中国超算“灵晟”重回TOP500榜首,不仅是中国再次证明自身在超算领域的顶尖实力,更为关键的是,“灵晟”是一台全国产、软硬件全栈自主可控的中国超算。
不过,位列TOP500榜首并不等同于在人工智能(AI)领域处于领先地位。因为,LineShine并未配备AI芯片,它采用的是纯CPU计算架构,因此它并不是全球最强的AI超算,不过它在模拟AI计算的基准测试当中排名第四。
245万个CPU核心,峰值性能达2.198ExaFlops
今年5月,芯智讯就曾发文深度介绍过这款由深圳国家超级计算中心(NSCC-SZ)开发的超算LineShine。
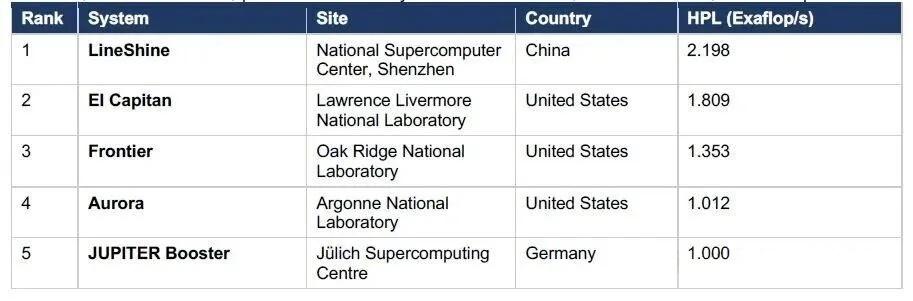
LineShine系统由20,480个计算节点构成,每个节点搭载2颗基于ARMv9架构的LX2处理器,主频 1.55 GHz,全系统总计40,960颗处理器、超过245万个CPU核心。
具体来说,每个LX2处理器内集成了两个计算芯粒,总共304个CPU核心,分为8个集群,每个集群拥有38个CPU核心,每个核心配备32 KB的L1指令缓存和32 KB的L1数据缓存,而每个集群则共享一个28.5 MB的L2缓存和4GB的高带宽内存(HBM)。
所有CPU核心均支持Arm SVE(可伸缩向量扩展)和SME(可伸缩矩阵扩展),可直接高效处理FP64、FP32、BF16、FP16、INT8等多种数据格式的AI训练与推理任务。每个LX2处理器在FP64/FP32精度下分别可提供高达60.3/120.6 TFLOPS的算力,在BF16/FP16精度下可提供240 TFLOPS算力,在INT8精度下可特供960 TOPS算力。
LX2还采用了类似日本“富岳”超算A64FX处理器的混合内存设计:每个LX2处理器集成了8个总计32GB容量HBM高带宽内存,总带宽达到4TB/s,同时支持最高256GB的片外DDR5内存。这种设计使得CPU可以在同一内存空间内处理海量科学数据集,避免传统CPU-GPU异构架构中频繁的数据搬运开销。
此外,每个裸片内置专用的智能直接内存访问(SDMA)引擎,用于在HBM和128 GB片外DDR内存之间移动数据,这对于需要精细内存管理的AI训练负载尤为关键。节点之间通过中国自研的“灵渠”(LingQi)高速互连网络连接,该网络采用双平面、多轨胖树拓扑结构,每个节点的带宽为1.6 Tb/s。
整个LineShine系统包括40,960颗处理器,超过245万个CPU核心,分布在92个计算机柜中,拥有100万端口互连,36个网络机柜,67个存储柜,428个存储节点,10 TB/s存储带宽,总存储容量650 PB。

据TOP500官方数据显示,LineShine系统总功耗约为42.2兆瓦,能效比达到52.07 Gigaflops/w,高性能 Linpack (HPL) 基准测试以2.198 ExaFLOPS成绩位居第一。
同时,它在高性能共轭梯度(HPCG)基准测试排名中以22.00 HPCG-Petaflop/s的成绩位列第一。在HPL-MxP混合精度基准测试中,它取得每秒7.92 Exaflops的成绩,排名第四。
TOP500组织表示,其相对于HPL分数仅3.6倍的适度加速比,“表明这是一个纯CPU设计,没有配备专用的低精度加速器”。
另外需要指出的是,随着生成式AI的爆发,亚马逊、微软、谷歌等云巨头都构建了自己的庞大的AI数据中心,并将其调整为人工智能应用,而非传统的科学计算方法,但是大多数公司的AI数据中心却从未跻身TOP500强,因为他们并没有向TOP500组织提交它们的系统。
“如果超大规模数据中心运营商提交他们的系统,这个‘世界上最快的系统’甚至都进不了前五名,”加州大学全球冲突与合作研究所高级研究员吉米·古德里奇说。
“灵晟”为什么选择纯CPU架构?
当前超算系统普遍采用CPU+GPU异构计算架构。以马斯克旗下xAI的Colossus集群为参考,其理论峰值性能高达约498 ExaFLOPS,即使按照约15%的实际利用率,也能提供约75 ExaFLOPS的有效算力,远超LineShine系统的1.54 ExaFLOPS。此外,分析指出CPU-only系统在进行稠密AI计算时,其能效比和绝对算力密度通常低于专门的GPU加速器,这也是行业主流选择“CPU+GPU”异构路线的主要原因。
但是,基于CPU-only系统的AI和高性能计算超级计算机相比传统的异构CPU+GPU系统也有着多项优势,尤其是在结合AI训练与大规模数据摄取、预处理、存储交互、仿真和编排的复杂科学任务中。
具体来说,由于CPU-only系统都运行在同一处理器和内存空间上,它们避免了异构计算带来的许多复杂问题,比如昂贵且耗费带宽的CPU到GPU数据传输、复杂的编程模型、GPU内存限制以及加速器专用的软件栈。
CPU-only系统系统通过结合HBM和大容量DDR能力,可以拥有更大的连贯内存池,这对于处理海量的科学数据集、检索增强生成和长上下文窗口非常有用。
CPU-only系统也适合涉及不规则控制流、分布式I/O、通信密集流水线以及执行模式不高效映射到GPU的科学人工智能应用。
此外,CPU-only系统可以更自然地与传统高性能计算环境集成,执行常规超级计算机任务(如仿真),这对需要同时进行AI训练/推理和高性能计算的需求尤为有用。
最后,在美国持续限制高端GPU对华出口的背景下,中国转而发展CPU-only系统,摆脱了对英伟达GPU和CUDA软件生态系统等国外加速器和平台的依赖,实现了完全的自主可控。
深圳市科技创新局有关负责人在今年4月底介绍“灵晟”国产E级超级计算机系统时也表示,“灵晟”国产E级超算系统全面点亮并完成全机测试,是我国高端计算领域全栈自主可控的标志性成果。深圳正深入实施算力强基行动,构建全球领先的“通用算力+智能算力+超级算力”一体化体系。
需要指出的是,LineShine系统并非意在取代GPU超算集群,而是在特殊技术封锁背景下,为保障国家战略计算需求、探索自主技术路线而打造的关键“备份”与补充系统,尤其适用于将AI与大规模科学模拟、数据分析深度融合的“AI for Science”场景。







地址:深圳市龙华区大浪街道祥昭大厦17楼
Copyright © 2024 天明山科技集团


